广东交职院专区
基本信息
- 作品名称:
- 基于TFS(Taobao File System)的海量小文件分布式存储系统的架构与研究
- 大类:
- 自然科学类学术论文
- 小类:
- 信息技术
- 简介:
目的:分析海量小文件的存储及访问的解决方法,研究实例系统的架构方法及其在实际案例中的应用。
基本思路:
1、调查研究海量小文件访问及存储的现状及问题
2、研究TFS的结构及组成
3、研究并建立基于TFS架构实例系统
4、分析基于TFS的实例系统在实际中的应用
作品的科学性、先进性及独特之处
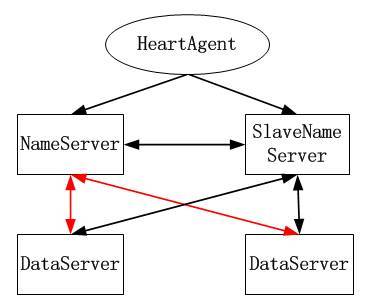
1、分布式系统实例系统摆脱了传统分布式文件系统依靠NameServer服务器进行分配存储池的资源,容易造成单节点故障的缺点,采用以文件名直接定位存储位置,客户端可以直接解析文件名得到文件的存储位置,直接访问存储服务器;
2、系统并发访问及存储能解决海量小文件同步的问题。
作品的实际应用价值和现实意义
实际价值:
1、本项目可以实现一个存储海量小文件的存储平台,属于TB乃至PB级的存储平台;
2、解决服务器后端存储平台解决海量小文件的读写超高磁盘IO等待的瓶颈;
3、解决web并发海量小文件的超长延时的问题。
现实意义:
1、参考该设计文档可以搭建解决并发海量小文件的分布式存储系统实例;
2、为高校建设信息资源库以及OA办公共享系统的存储架构提供参考方案;- 详细介绍:
该论文主要论述的是基于TFS(TaobaoFileSystem)分布式文件存储系统对高校资源共享系统的架构设计,同时也讨论如何利用好开源技术来解决存储的问题,从而节省更多不必要的成本。
该论文首先是对现在的互联网情况进行分析,得出在web2.0时代我们所遇到的一些问题,海量的小文件对web2.0时代发展的限制,并造成了需要很高的成本来进行架构、维护等问题,还详细列举了海量小文件所造成的各种问题,并对现阶段比较火的分布式文件系统技术进行分析,通过对多个文件分布存储系统的分析,如hadoop、GFS等,我们发现在对小文件的支持上不是不能很好的解决问题就是技术没有开放,我们不能使用。
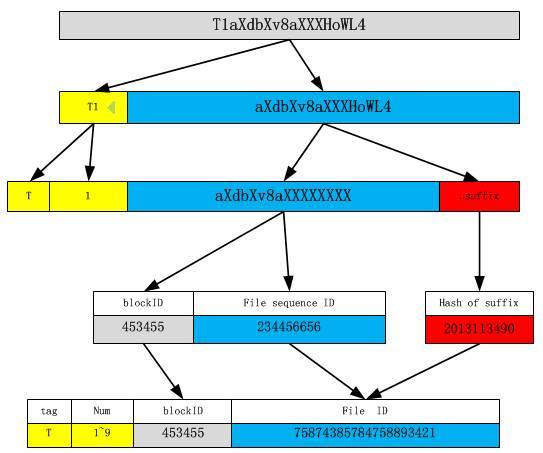
接着我们将目标投向国内淘宝团队提供的开源技术TFS(TaobaoFileSystem),我们发现这是一个对小文件的存储支持的很好的一个存储平台,通过创新的文件名设计来定位文件存储位置,将解码负载转移到客户端,充分利用客户端资源,巧妙的解决了大量元数据存储的问题,降低的服务器成本,同时采用HA高可用负载技术,避免了单点故障的问题。
最后我们通过分析了高校信息资源库的基本情况,如大量文档文件存储的问题,然后针对TFS分布式文件存储系统对海量小文件支持友好的特性,对高校的信息资源库的存储平台进行架构设计,满足海量小文件存储,并降低服务器成本。
1、小文件存储的现状
之所以会讨论海量小文件的存储问题,就是在这个Web2.0的时代里,这是一个我们不能回避的问题了,目前就我们国家来说,网民的数量已经增长到5.6个亿了,在web2.0的时代每个用户都是网络信息的创造者,互联网的信息量成几何级增长,庞大的用户量会产生庞大的信息量,而庞大的信息量又是对互联网后台技术架构的冲击。海量的小文件产生,高并发,随机性,流量大,等等这些随时都能让网络服务崩溃掉。我们可以列举一下这些根本性的问题:
海量小文件:电子书、文档、邮件、图片等等,都是小文件的主要来源,都是KB级的,几KB,几十KB占了很大部分,一个100MB的文件传输可以很快,可是100MB大概分为10000个10kb的小文件来传输,那么就需要很长时间了;
海量小文件索引检索:在现有的文件存储系统中,单个目录下文件数超过一定数量后索引就会急剧下降,而采用多级目录存储也同样的限制,超过临界值变会有很大的速度下降;
随机性,Cache命中率低:一般为了提高访问速度会进行数据缓存,可往往是数据的访问随机性很大,跨度很厉害,缓存数据的命中率及其低下;
并发性高:海量数据的并发请求,会使得服务器的负载变得很大,一般表现为请求延时,当超过一定压力后,服务器会选择罢工,也就是宕机了;
容灾备份:这个说到底还是小文件的传输问题,速率极其低下,可用性很低,而且常常造成数据丢失,不能很好的管理,海量的数据备份会消耗大量的时间和系统资源。
碎片化,占用存储空间:大量的小文件占据着比本身文件大小还大的存储空间。
以上这些都是我们在实际生产环境中会遇到的问题,而且每一个都是很棘手问题。
但是具体有没有一种好的设计方案来解决这些为题呢?其实早在十年以前谷歌就已经解决了这类问题,但是由于没有技术没有开源出来,所以我们只能通过一些论文得知其设计思想的大概,谷歌是采用自己的GFS(google file system),通过数据流的形式来存储大量的小文件,并通过一种叫做chunk的方式进存储(可以理解为数据块,每个64MB),避免碎片化的问题,用NameServer来记录存储每个chunk的元数据,这样客户端在访问数据的时候可以直接访问存储数据,减少NameServer的压力,简化了设计。对于容灾备份,谷歌并没有采用RAID机制,而是直接用优化算法将一份数据复制几份到其他服务器,这样反而降低了成本,也提高磁盘的读写性能。
源于谷歌的这种设计思想,以致后来apache开发的hadoop分布式存储系统也有类似的架构,但是hadoop针对的对象偏向于大文件,大数据,对小文件的支持并不是很友好,不过也有一些例外,比如中国电子教学共享系统Bluesky就是采用HDFS进行存储的,他们具体是怎样做到的呢?基于hadoop都是要根据自己的需求进行二次开发,编写程序来实现的。设计思想是根据一种web与地理信息系统(GIS)产生的一种新系统WebGIS。结合WebGIS中数据的相关性特征,以一种地理位置相近的数据合并为大文件,并在大文件里将这些小文件建立索引的思路,将教学资源里的同一个科目,种类等某种相关信息进行归类合并,建立索引。当用户在访问Bulesky资源系统里面的ppt文件、doc文档等等时,同属于相关的PPT、doc等文件也会被预先加载到内存,以提高其访问效率。这样一来,用户在连续的访问时,速度会明显提高。但是,我们并不建议采用这种设计方案。主要的原因有一下几个:
可维护性差,运营维护成本比较大;
Hadoop file system是采用java语言开发的,在实际上的服务器集群生产环境效率并不是很高效,经常是以机器换性能,不能够很好的利用到每台机器的实际性能,需要花费大量的资金用于购买设备;
不能解决客户端访问的随机性,而且采用相关性数据的加载,当并发足够大的时候很容易收到内存溢出攻击。
综合以上的分析情况,对于一个好的文件存储系统,我们认为应该具备哪些性能特点呢?
采用可靠,强大的开发语言,对于服务器集群而言,最重要的是稳定性,其次就是系统资源的占用不能过大,数据处理效率要高,我们可以对比一下我们所熟悉的Android和苹果的IOS,Android是采用java开发的,而IOS是采用古老的ObjectivC(属于C语言)开发的,两个系统的稳定性以及可靠性我们可以很清楚的感受到;
不能存在单点故障:现在很多分布式存储会存在单点故障的风险,一旦单点存在瓶颈,那么将大大限制该系统的扩张性以及可靠性,如NFS;
对于集群里的每台机器都能尽可能的优化,提高其利用率,而不是存在以机器数量换性能的情况;
可维护性较高,不会造成一个集群一旦投入生产环境,需要雇用一个专业能力很强的技术人员进行维护;
具有很强的可拓展性,随着数据的增多,以及业务的拓展,需要集群在生产环境中能适时的根据需求进行扩展,提升;
当然,除了以上这些,还有许许多多的问题会存在,比如元数据数量过多,索引慢,磁盘的I/O瓶颈等等,在一个实际的生产环境中,需要注意的会更多更多,很多时候还需要定制优化,比如上文提到的谷歌的服务器,都是谷歌内部定制的,但是这些技术很多都是没有公开的,都是受到专利保护的。
2、基于TFS的解决方案
其实,在今年的“双十一”光棍节中,淘宝再一次引起了人们的关注,我们来看看下面的一组数据:2012.11.11当天,支付宝总销售额为191亿元。11日零时开始的第一分钟,超过 1000万人登陆天猫平台;11日当天。平台总共涌入2.13亿网民;11日当天的订单量为1亿580万笔;支付宝核心数据库集群处理了41亿个事务,执行285亿次SQL数据语言,访问1931亿次内存数据块。核心MySQL(开源数据库管理系统)集群一天支持了20亿个事务;看完这组数据,足以感到震撼,如此之高的并发,流量如此之大,可见其后端服务集群是多么稳定,强大呀。我们可以打开淘宝首页,或者天猫首页,你会发现其实每个页面都会有很多图片,原图,缩略图等等,而且你并不会觉得图片加载不了,或者太慢,即使我们刷屏的话,也就好似不断的跳转页面,也不会觉得有什么图片加载过慢,或者不能显示的问题,或者说出现问题的情况极少。
我们接下来再看一组数据,这是淘宝系统公布的一组数据:
图片的总量为:998TB
文件数量为:286亿多个(80%为小于18kb的对象,8kb以下的更是占到了61%)
图片的平均大小:17.45kb
从这组数据可以看到,着写都是很典型的小文件,如此大量的小文件,如果以现在普通分布式文件系统,或者普通的文件系统来进行架构,那简直就是一种噩梦,首先是会产生大量的元数据,其次是在备份问题998TB,以2MB/S,这个要备份到什么时候?再而就是以现在的普通的机械磁盘来说,超高的I/O等待就会让你抓狂,最后是根据淘宝的实际情况来看,热点数据的命中是很难把握的,对数据缓存加载到内存这个实现不是很容易。
分析完数据,回过头来我们再分析淘宝的存储系统——TFS(taobao file system),这个就是淘宝现在生产环境中在使用的存储系统,先应用官方的一段描述:
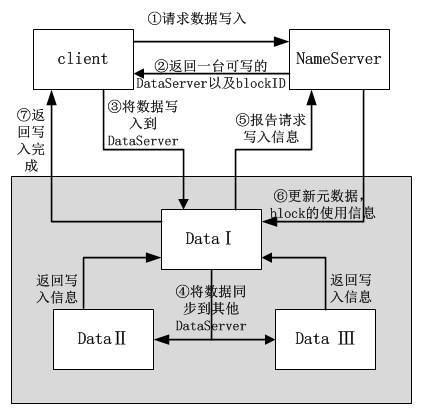
TFS是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,满足了淘宝对小文件存储的需求,被广泛地应用在淘宝各项应用中。它采用了HA架构和平滑扩容,保证了整个文件系统的可用性和扩展性。同时扁平化的数据组织结构,可将文件名映射到文件的物理地址,简化了文件的访问流程,一定程度上为TFS提供了良好的读写性能。一个TFS集群由两个!NameServer节点(一主一备)和多个!DataServer节点组成。这些服务程序都是作为一个用户级的程序运行在普通Linux机器上的。- 获奖情况:
广东交通职业技术学院第四届“挑战杯”广东大学生课外学术科技作品竞赛三等奖