
作者:肖光烜 吕天 李永威 计算机科学与技术系
指导老师:刘知远 计算机科学与技术系
关键词:深度学习、计算机视觉、甲骨文、自然语言处理
摘要
深度学习需要大数据驱动,而在甲骨文释读领域还未有合适的大规模数据集。我们构建了一个组织良好、噪声小的甲骨文数据集,我们相信这种数据集能够为今后的自动化甲骨文释读的研究做出贡献。
在我们构造的数据集的基础上,我们采用计算机视觉领域的技术做到甲骨文字“分类”,即对一个甲骨文图片给出其现代汉语或古汉语中对应的汉字。同时,我们训练了一个能够自动构建甲骨文的生成对抗网络,以期能够捕捉甲骨文中的内在结构并发现未发现的甲骨文。
构建数据集
我们对已有的纸质甲骨文词典进行了扫描和编排,利用滤波和二值化等图像处理技术收集了一个组织良好、噪声小、全面的甲骨文数据集。该数据集由7000余个甲骨文样例组成,共有542个多于10个样例的甲骨文,覆盖了最常见的甲骨文,具有较好的代表性。
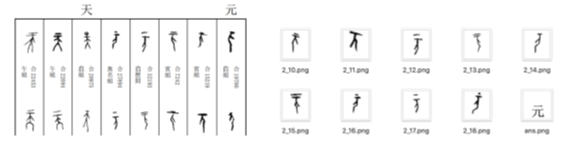
图 1甲骨文字典(左)与对应构造好的数据集(右)
甲骨文识别
利用目前最先进的图像识别网络ResNet和DenseNet,我们在甲骨文识别任务上达到了很高的准确率。由于甲骨文识别可以减轻考古人员筛选甲片的工作量并提高准确度,这一结果具有重要现实意义。使用我们提出的数据集进行训练,图像识别网络可以区分非常形近的甲骨文,例如“月”和“夕”。这也说明我们提出的数据集具有良好的清洁度和代表性。
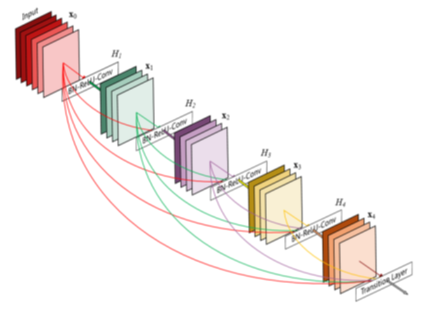
图 2DenseNet网络结构
|
Model |
Top-1 Accuracy(%) |
Top-5 Accuracy(%) |
|
ResNet-152 |
38.72 |
63.72 |
|
DenseNet-121 |
75.14 |
88.82 |
表格 1 甲骨文识别准确度
甲骨文生成
我们期望利用生成对抗网络(GAN)获得不存在的甲骨文,从而得到甲骨文字形的一般形式信息。

图 3生成对抗网络结构
但是最原始的生成对抗网络产生了严重的过拟合现象,因此我们换用了更为先进的WGAN,得到了更为多样化的甲骨文生成结果。

图 4GAN和WGAN生成的不存在的甲骨文及其对应的汉字




